Introduction
As organizations generate increasingly large volumes of text data, traditional manual review methods become difficult to scale. Businesses today collect information across reports, exported databases, logs, transcripts, research archives, documents, communication records, and operational text files. While collecting information has become easier, extracting meaningful insights from that information remains a major challenge.
Large raw text files often contain valuable business intelligence, but without the right analysis strategy, processing becomes expensive, slow, repetitive, and difficult to manage.
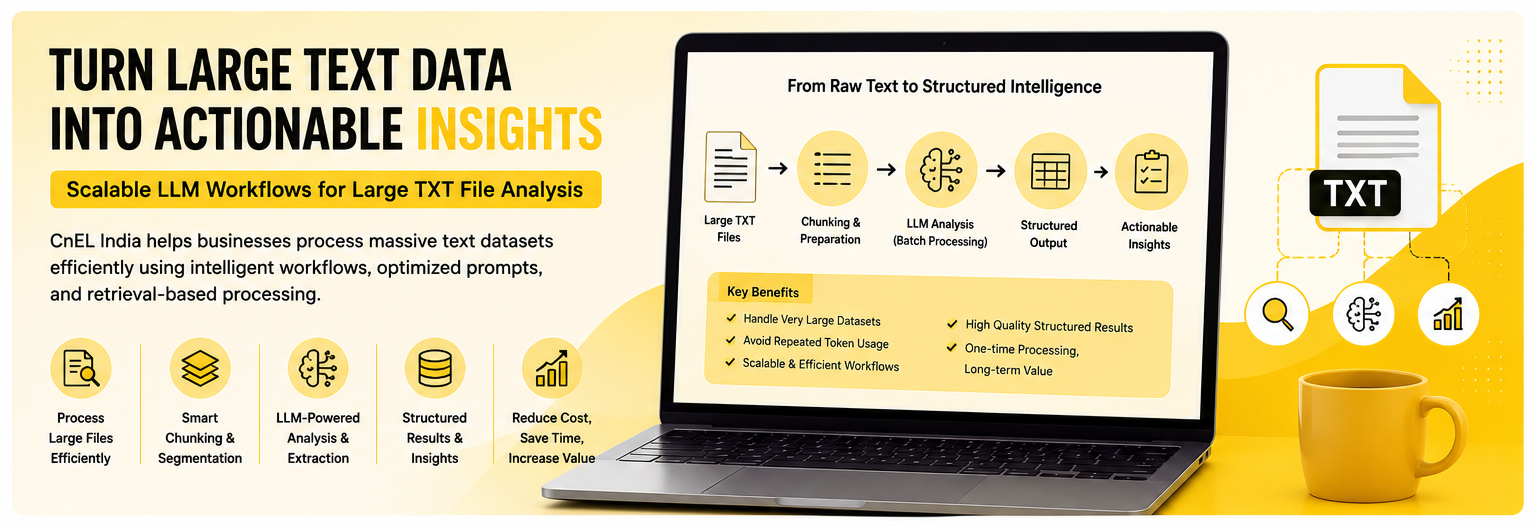
This case study explains how CnEL India can design and implement a scalable large-text analysis workflow that enables efficient scanning, structured extraction, intelligent processing, and repeatable analysis across very large TXT datasets.
The objective is not simply to process massive files all at once. Instead, the goal is to build an intelligent workflow that reduces unnecessary processing, improves result quality, and creates a repeatable system capable of handling growing data volumes.
This project focuses on creating a practical framework that supports:
- Large text processing
- Structured extraction workflows
- Efficient prompt execution
- Scalable document analysis
- Intelligent search and retrieval
- Reduced processing costs
- One-time and repeatable analysis scenarios
CnEL India approaches this challenge as both an architecture and operational optimization project.
Understanding the Business Requirement
The requirement is not basic document summarization.
The client has extremely large TXT files and wants to:
- Run multiple analysis requests across data
- Avoid repeatedly loading raw files
- Reduce processing inefficiencies
- Extract structured outcomes
- Process files at scale
- Retain only valuable insights
The solution must balance:
- Accuracy
- Processing speed
- Cost efficiency
- Long-term maintainability
CnEL India treats this as a workflow engineering challenge rather than a single processing task.
The Core Challenge of Large Text Processing
Very large datasets introduce several operational challenges.
Common limitations include:
- Excessive processing requirements
- Repeated data loading
- Information fragmentation
- Slow execution times
- High operational costs
- Difficult result validation
Traditional copy-and-paste approaches quickly become impractical.
CnEL India builds systems designed specifically for large-scale text intelligence.
Designing a Scalable Processing Strategy
The first step is understanding the nature of the files.
CnEL India evaluates:
- File size
- Content structure
- Data patterns
- Expected outputs
- Frequency of analysis
This assessment determines the most efficient workflow structure.
Intelligent Segmentation Approach
Processing massive text as one block creates inefficiency.
CnEL India divides content into structured segments.
Segmentation strategy considers:
- Topic boundaries
- Logical context
- Information continuity
- Processing objectives
The goal is preserving meaning while improving efficiency.
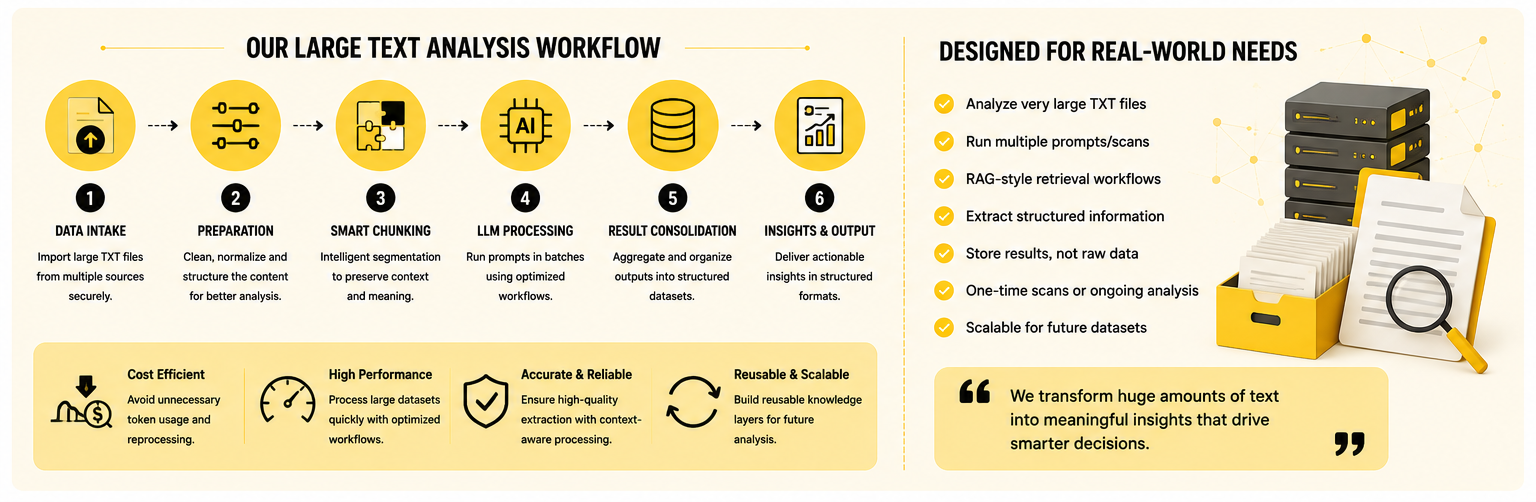
Creating an Analysis Pipeline
Instead of repeatedly scanning entire datasets, CnEL India creates staged processing pipelines.
The workflow typically includes:
Stage 1 — Data Intake
Raw files enter the processing environment.
Stage 2 — Content Preparation
Content normalization and structure preparation.
Stage 3 — Intelligent Segmentation
Breaking content into manageable units.
Stage 4 — Processing Execution
Applying analytical instructions.
Stage 5 — Result Consolidation
Combining useful findings.
Stage 6 — Structured Storage
Preserving outputs for future access.
This architecture reduces duplication.
Minimizing Reprocessing Costs
One major objective is avoiding repeated full-file execution.
CnEL India solves this by creating:
- Persistent processed outputs
- Indexed result layers
- Reusable analytical structures
- Stored extracted knowledge
Future requests access processed information instead of restarting.
Designing Efficient Query Workflows
Different business questions require different approaches.
CnEL India supports workflows for:
- Search-based exploration
- Structured extraction
- Pattern identification
- Classification
- Insight generation
- Comparative analysis
The architecture remains flexible.
Structured Output Generation
Raw text alone has limited value.
CnEL India transforms outputs into structured formats such as:
- Organized summaries
- Categorized findings
- Confidence indicators
- Extracted entities
- Relationship mapping
Structured outputs improve usability.
Reducing Processing Waste
Efficiency directly impacts scalability.
CnEL India reduces unnecessary operations through:
- Selective retrieval
- Context prioritization
- Incremental processing
- Focused execution logic
This improves both speed and operational cost.
Designing Retrieval-Oriented Processing
When datasets become extremely large, searching intelligently becomes essential.
CnEL India creates retrieval systems that:
- Surface relevant information quickly
- Avoid full-file scans
- Preserve contextual accuracy
- Support repeated analysis
This creates long-term operational value.
Supporting Multiple Prompt Workflows
The requirement includes running many analytical instructions.
CnEL India designs workflows capable of:
- Sequential analysis
- Parallel execution
- Multi-pass review
- Layered extraction
Each analytical pass contributes new value without restarting the process.
Building Reusable Knowledge Layers
Large text analysis becomes more powerful over time.
CnEL India creates reusable information layers including:
- Indexed findings
- Extracted structures
- Relationship maps
- Processed datasets
This allows future analysis to become faster.
Handling One-Time Large Scans
Some projects require only a single processing cycle.
CnEL India designs one-time execution strategies that focus on:
- Maximum extraction quality
- Controlled processing cost
- Clean result organization
Outputs remain usable after execution completes.]
Supporting Ongoing Analysis Scenarios
Other businesses require recurring scans.
For ongoing environments, CnEL India builds systems that support:
- Incremental updates
- Selective refresh
- Historical comparison
- Result versioning
This prevents unnecessary rebuilding.
Data Organization and Governance
Large datasets require structured management.
CnEL India organizes:
- Raw source layers
- Processed outputs
- Result archives
- Analytical history
Clear organization improves reliability.
Quality Control Framework
Large-scale analysis requires validation.
CnEL India introduces quality controls including:
- Output consistency checks
- Context verification
- Extraction accuracy reviews
- Duplicate detection
Validation improves trust in results.
Performance Optimization Strategy
Processing efficiency remains central.
CnEL India optimizes:
- Throughput
- Execution cycles
- Storage efficiency
- Resource utilization
This enables practical scaling.
Security and Controlled Access
Text files may contain sensitive information.
CnEL India incorporates:
- Controlled environments
- Data separation
- Structured access policies
- Protected storage practices
Security remains part of the architecture.
Dashboard and Operational Visibility
Large processing projects benefit from visibility.
CnEL India may support operational layers that provide:
- Progress tracking
- Result summaries
- Analysis history
- Output review workflows
Visibility improves decision-making.
Collaboration and Delivery Process
Projects are delivered through structured phases.
Discovery
Understand objectives.
Workflow Design
Build processing logic.
Validation
Test execution quality.
Deployment
Enable operational use.
Optimization
Improve based on usage.
Challenges Solved by CnEL India
Organizations often struggle with:
- Large unstructured datasets
- Slow analysis cycles
- Excessive operational cost
- Duplicate processing
- Information overload
CnEL India addresses these challenges through intelligent workflow design.
Business Outcomes Delivered
By implementing this solution, businesses gain:
- Faster insight generation
- Lower processing waste
- More reliable extraction
- Better scalability
- Reduced manual effort
The result becomes a repeatable analysis capability.
Why CnEL India for Large Text Analysis Projects
CnEL India combines:
- Workflow architecture expertise
- Data processing strategy
- Scalable system thinking
- Structured result generation
- Long-term operational planning
The focus remains on building solutions that continue creating value after the initial processing cycle.
Long-Term Impact
Large-scale text processing is not only about automation.
It creates:
- Better decision-making
- Faster research cycles
- Improved operational efficiency
- Reusable business intelligence
Organizations gain the ability to transform raw information into structured knowledge.
Conclusion
This case study demonstrates how CnEL India can design and implement a scalable large-text analysis workflow that enables efficient processing, intelligent segmentation, structured extraction, retrieval-oriented operations, and reusable insight generation across massive TXT datasets.
Rather than treating large files as isolated processing tasks, the approach creates a long-term analytical framework designed for speed, efficiency, and sustainable growth.
By combining workflow design, operational intelligence, structured outputs, and scalable architecture, CnEL India helps businesses unlock value from large text datasets while minimizing unnecessary processing effort and maximizing insight generation.