Introduction: When AI Learns from Code, Quality Becomes Critical
Artificial Intelligence is transforming software development faster than ever before. Modern AI systems can now generate coding challenges, write functions, suggest fixes, and even build application logic automatically.
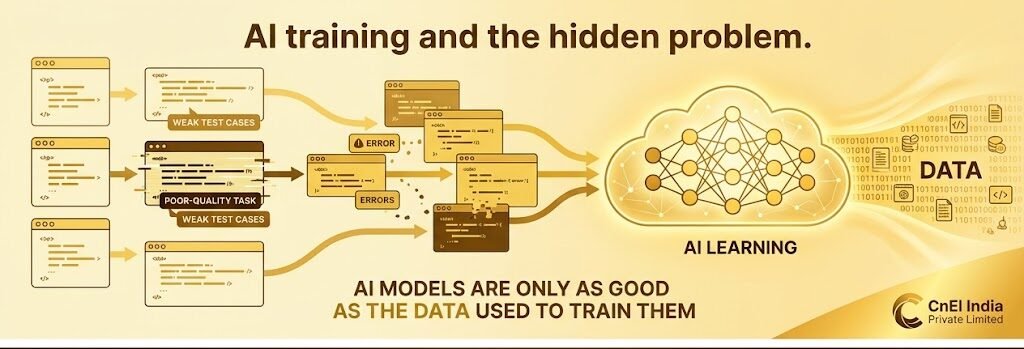
But there’s a hidden problem behind this rapid evolution.
AI models are only as good as the data used to train them.
If poor-quality coding tasks, weak test cases, or incorrect validations enter the training pipeline, the consequences scale rapidly across thousands—or even millions—of generated outputs.
This creates a serious industry challenge:
How do you ensure that AI-generated programming tasks are technically correct, logically sound, and properly validated before they are used to train intelligent systems?
That’s exactly where CnEl India Private Limited stepped in.
This case study explores how our engineering review team helped improve the reliability and accuracy of AI-generated coding tasks through advanced software code review, test validation, and technical quality analysis across multiple programming languages.
The Growing Need for AI Code Validation
As AI-generated development workflows expanded, organizations began facing a new category of problems:
- Poorly defined coding requirements
- Ambiguous problem statements
- Weak or incomplete automated tests
- Incorrect assumptions in evaluation logic
- False-positive test results
- Solutions passing tests without actually solving the problem
The client needed experienced software engineers who could think critically—not just execute tasks mechanically.
They required professionals capable of reviewing complex coding challenges from a real engineering perspective.
The objective was simple but extremely high-impact:
Ensure AI training tasks represent real software engineering quality standards.
Why This Project Was Different
Most software projects focus on building applications.
This project focused on validating intelligence itself.
Instead of writing production code, the responsibility was to evaluate whether generated programming tasks were technically trustworthy.
That meant asking deeper questions such as:
- Does the challenge truly reflect the intended problem?
- Are the requirements logically complete?
- Can developers interpret the task consistently?
- Do the tests genuinely validate correctness?
- Could flawed tests allow incorrect solutions to pass?
- Does passing all tests actually mean the solution works properly?
This required more than coding knowledge.
It required engineering judgment.
The Challenge: AI Can Generate Volume—But Not Always Precision
AI-generated coding tasks were being produced rapidly across multiple programming languages, including:
- Python
- JavaScript
- TypeScript
- Go
- Rust
- Java
While the generation speed was impressive, consistency and reliability became major concerns.
Several hidden issues started appearing:
Ambiguous Requirements
Some tasks lacked clarity, making multiple interpretations possible.
Weak Test Coverage
Certain tests validated only basic scenarios while ignoring edge cases.
False Success Validation
Some incorrect solutions still passed all tests due to flawed testing logic.
Inconsistent Technical Standards
Generated tasks varied significantly in quality and complexity.
Scalable Error Propagation
A single flawed coding challenge could negatively impact large-scale AI training datasets.
This made expert review absolutely essential.
Our Approach: Engineering-Level Quality Control
At CnEl India Private Limited, we approached the project as a structured software validation system rather than a basic review process.
We built a workflow centered around four key principles:
1. Requirement Clarity
2. Behavioral Validation
3. Technical Accuracy
4. Scalable Consistency
The goal was not just to detect mistakes.
It was to improve the quality standard of the entire AI training ecosystem.
Phase 1: Requirement Analysis
Every coding challenge first underwent deep requirement evaluation.
Our review engineers analyzed whether:
- The problem statement was logically complete
- Inputs and outputs were clearly defined
- Edge cases were explained properly
- Constraints were technically reasonable
- Expected behavior was unambiguous
We treated requirements as the foundation of correctness.
Because if the problem itself is unclear, every downstream process becomes unreliable.
Phase 2: Test Validation Review
This became the most critical layer of the project.
The client considered automated tests as the “source of truth.”
That meant any testing mistake could scale directly into AI model training.
Our team carefully reviewed whether the tests:
- Correctly validated intended behavior
- Covered realistic edge cases
- Prevented shortcut solutions
- Rejected logically incorrect implementations
- Aligned fully with task requirements
This process required extremely high attention to detail.
Sometimes the challenge description looked correct—but the tests were flawed.
Other times the tests were strong, but the requirements were incomplete.
Both scenarios created risk.
Phase 3: Behavioral Accuracy Evaluation
One of the most advanced parts of the review process involved validating behavioral correctness.
Instead of asking:
“Does the code pass?”
We asked:
“Does the solution genuinely solve the intended problem?”
This distinction was crucial.
Many generated tasks allowed solutions that technically passed the tests while still being logically incorrect in real-world conditions.
Our engineers analyzed:
- Hidden assumptions
- Potential exploit paths
- Weak validation logic
- Incomplete behavioral checks
This prevented low-quality training examples from entering the system.
Phase 4: Multi-Language Technical Review
The project involved several programming languages, each with unique characteristics.
This required engineers capable of understanding:
- Language-specific behavior
- Runtime considerations
- Testing methodologies
- Code structure patterns
- Common implementation pitfalls
Our team built standardized review criteria while still respecting language-specific best practices.
This created consistency across the entire review pipeline.
Phase 5: Edge Case & Failure Scenario Analysis
One of the biggest weaknesses in AI-generated coding tasks was insufficient edge-case coverage.
We specifically tested for:
- Invalid inputs
- Boundary conditions
- Unexpected behavior
- Performance limitations
- Logical failure points
This dramatically improved the robustness of validation systems.
Phase 6: Open-Source Level Engineering Standards
To ensure professional-grade quality, we applied review standards commonly used in mature software engineering environments.
This included:
- Code readability evaluation
- Logical consistency checks
- Testing completeness analysis
- Maintainability considerations
- Structural review discipline
The focus was not academic perfection.
It was practical engineering reliability.

The Transformation
Before expert review implementation:
- Tasks varied heavily in quality
- Some tests validated incorrect behavior
- Ambiguity caused inconsistent interpretations
- AI training reliability was at risk
After the review framework was established:
- Task quality became significantly more consistent
- Test reliability improved dramatically
- Edge cases were properly validated
- Technical accuracy increased across datasets
- AI training confidence improved substantially
The difference was measurable.
Results Achieved
1. Higher AI Training Quality
Validated coding tasks produced stronger and more reliable training datasets.
2. Reduced Error Propagation
Incorrect logic was identified before reaching large-scale AI systems.
3. Stronger Testing Standards
Automated tests became more comprehensive and behavior-focused.
4. Improved Technical Consistency
Multi-language coding tasks followed stronger engineering standards.
5. Better Problem Definition
Requirements became clearer, reducing ambiguity and confusion.
6. Increased Trust in Generated Tasks
The review pipeline improved confidence across the entire development workflow.
What Made This Project Unique
Most code review projects focus on improving software.
This project focused on improving intelligence training systems.
What made CnEl India Private Limited different:
- Deep engineering analysis
- Multi-language expertise
- Strong understanding of automated testing
- Real-world production experience
- Behavioral correctness evaluation
- High-detail review methodology
We didn’t just review code.
We reviewed the quality of machine learning inputs that shape future AI behavior.
Key Insight from the Project
One important realization stood out clearly:
“Passing tests does not always mean the solution is correct.”
This project highlighted the growing importance of intelligent validation systems in AI-assisted software development.
As AI-generated code becomes more common, human engineering judgment becomes even more valuable.
Long-Term Impact
The review framework created through this project established a scalable quality control system capable of supporting:
- Large-scale AI training operations
- Higher-quality coding datasets
- Better engineering consistency
- More trustworthy validation pipelines
Most importantly, it reduced the risk of flawed logic propagating into future AI systems.
Future Opportunities
The system can continue evolving with:
- Advanced behavioral analysis
- Intelligent anomaly detection
- Deeper edge-case simulation
- Automated quality scoring models
- Scalable validation frameworks for complex enterprise systems
The future of AI training will increasingly depend on review quality—and this project created a strong foundation for that future.
Conclusion
As AI-generated development workflows continue expanding, the importance of technical validation becomes more critical than ever.
Through structured engineering review, behavioral analysis, and advanced testing validation, CnEl India Private Limited helped strengthen the quality and reliability of AI training tasks across multiple programming languages.
The project demonstrated that successful AI systems are not built only through generation.
They are built through intelligent validation.
Because in the world of AI-assisted software engineering, one weak test can create thousands of incorrect outcomes.
And one strong review can prevent them all. 🚀